Yle uutisoi juhannuksen alla: Tutustu heihin – 100 kiinnostavaa suomalaista Twitterissä. Amatöörilouhijalle tällainen kotimainen Twitter-ryhmä tarjoaa mukavan tutkimuskohteen. Mitä sanoja top-tweettajat käyttävät? Minkähän takia? Missä yhteydessä?
Blogista Heuristic Andrew löytyi selkeä ohje juuri tähän, tekstin louhintaan Twitteristä R:n avulla.
Hankalinta on saada tarpeeksi louhittavaa. Kohtuullisella hikoilulla sain koottua listalta reilut 500 tweettiä. En juuri tunne Twitterin API:a, joten saatoin hyvinkin olla väärän lähteen äärellä. Olisiko statuspäivitykset pitänyt sittenkin kerätä listan sijaan jäsenten omalta aikajanalta? Harkitsin tätä. Idea kuivahti alkuunsa siihen, että en pystynyt poimimaan rajapinnan kautta listan kaikkia jäseniä vaan vain 20. Joistakin foorumikirjoituksista jäi itämään epäilys, että tämä olisi API:n rajoitus. Luultavammin rajat ovat kuitenkin näiden korvien välissä. No, hyvä että materiaalia on edes jonkin verran.
R-koodin seasta löytyy kommentteja työn etenemisestä ja havaintoja tuloksista. Silmiinpistävää on sanaston heterogeenisuus. Esiin nousevat oikeastaan vain Twitter-kommunikoinnin säätimet, sanat joilla osoitetaan mistä oma teksti on peräisin. Aineisto on lisäksi monikielistä, joka vähentää sanojen toistumistiheyttä näin pienessä otoksessa.
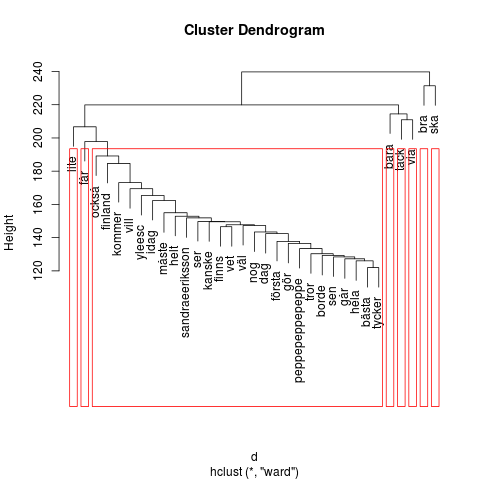
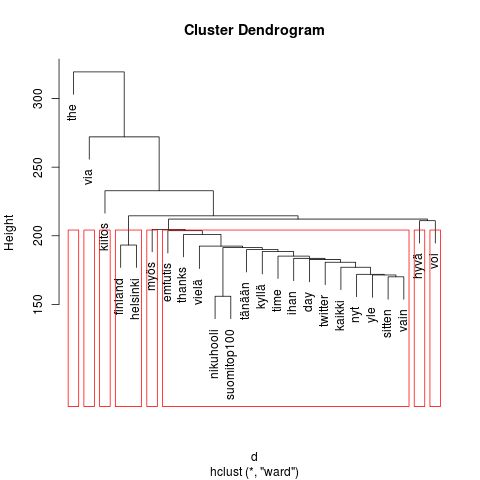
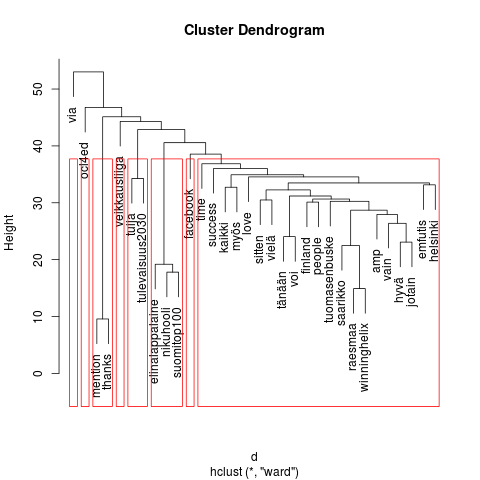
Kuten Heuristic Andrew, minäkin tein ryhmittelyanalyysin (cluster). Sen kuvaus on puumainen dendrogrammi. Mitä ylempänä oksa on, sitä enemmän on sen lehvästössä olevien sanojen esiintymisiä. Lähekkäin ja saman punaisen kehyksen sisällä olevat oksat kertovat siitä, että niiden sanoilla on tiettyä yhteyttä toisiinsa. Kehyksiä on tässä seitsemän, kokeilin pienempääkin. Oikeaan laitaan syntyi nyt hieman turhankin iso kaatoluokka.
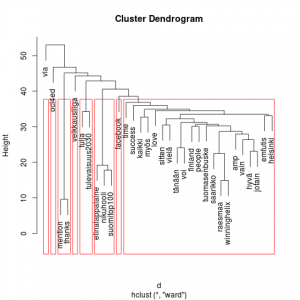
Dendrogrammin lukeminen on työlästä, koska niskaa pitää kääntää 90 astetta vasempaan. Epäilemättä löytyy tapa, jolla kääntyy graafi, ei pää.
Tämän harjoituksen pohjalta ei pysty sanomaan juuri mitään siitä, mitä, miten ja miksi Suomi twiittaa. Joitakin arvailuja voi esittää. Saattaa olla, että sanonnat (quote) ja lainaukset (via) ovat melko yleisiä. Mahdollisesti jotkut listan jäsenet ovat suositumpia viittauksen kohteita kuin muut. Jälkimmäinen päätelmä on itse asiassa tavallaan louhinnan sivutuote; samalla kun kaikki välimerkit siivottiin pois, lähti myös käyttäjänimen edestä @-merkki, jolloin henkilöä kuvaavasta nimestä tuli ns. tavallinen sana.