HS Open #2
HS Open kakkonen on huomenna, ja sinne olen minäkin menossa. Mielenkiintoinen päivä tulossa! Luupin alla ovat mm. eduskuntavaalit 2011. Rahoittajia löytyi, ehdokkaita oli, vaalit käytiin. Mitä muuta tästä spektaakkelista voi päätellä numeroiden valossa?
Lähdetään liikkeelle datasta.
Keskeistä aineistoa HS Open kakkosen Politiikka-ryhmälle ovat ehdokkaiden ilmoitukset kampanjoiden menoista ja ilmoitukset tukijoista. Arvokasta taustainformaatiota tuovat mm. YLE:n vaalikonetiedot.
Kaksi taulukkoa, kaksi omistajatahoa. Voiko taulukot yhdistää jonkin yhteisen, uniikin sarakkeen avulla? Ei voi, näillä tiedoilla. Mitään Vaaliehdokas-ID -avainta ei ole olemassa. Henkilötunnus tietysti kaikilla ehdokkailla on, mutta sitä ei saa julkaista eikä hyödyntää. YLE:n taulukkorivit (ehdokkaat) on yksilöity ID-numerolla, mutta se on taulukon tuottamisen sivutuote. Ehdokasnumero taas on vaalipiirikohtainen. Puoluerahoitusvalvonnan aineistossa ei ole mitään avainsaraketta. Tarvitaan siis yhteinen nimittäjä.
YLE:n aineistossa on mainittu ehdokkaista sukunimi ja kutsumaetunimi. Puoluerahoitusvalvonnan datassa taas sukunimi ja kaikki nimet, joista jokin on todennäköisesti kutsumanimi. Riittäisikö etu- ja sukunimen yhdistäminen avaimeksi? Ehkä ei, sillä kaimoja saattaa olla. Puolueen lyhenteen lisääminen perään olisi kai jo aika varmaa? Harmi, että lyhenne löytyy vain rahoitusdatasta, ei YLE:ltä.
Ajatus: lähes jokaisella ehdokkaalla vaikutti tällä kerralla olevan oma vaali-web-domain. Olisiko jonkun jossakin kannattanut tallentaa se?
Käytin yhteisen avaimen muodostamisen yrittämiseen useita tunteja. Lopputulos: ei tullut avainta, mutta tulipa kokemusta datan siivoamis- ja esitystyökaluista Google Refine ja Google Fusion Tables. Ynnä hämmennystä ja lievää manailua Google Docs -hipsuista ja muista yllätyksistä.
Google Refine
Google Refine (entinen Freebase Gridworks) on näpsäkkä työkalu. Esimerkiksi data.gov.uk on käyttänyt sitä omissa yhdistetyn avoimen datan hankkeissaan. Jeni Tennisonilta löytyy selkeäsanainen esitys aiheesta. Googlen pari omaa esittelyvideota kannattaa katsoa. Niillä pääsee hyvin alkuun.
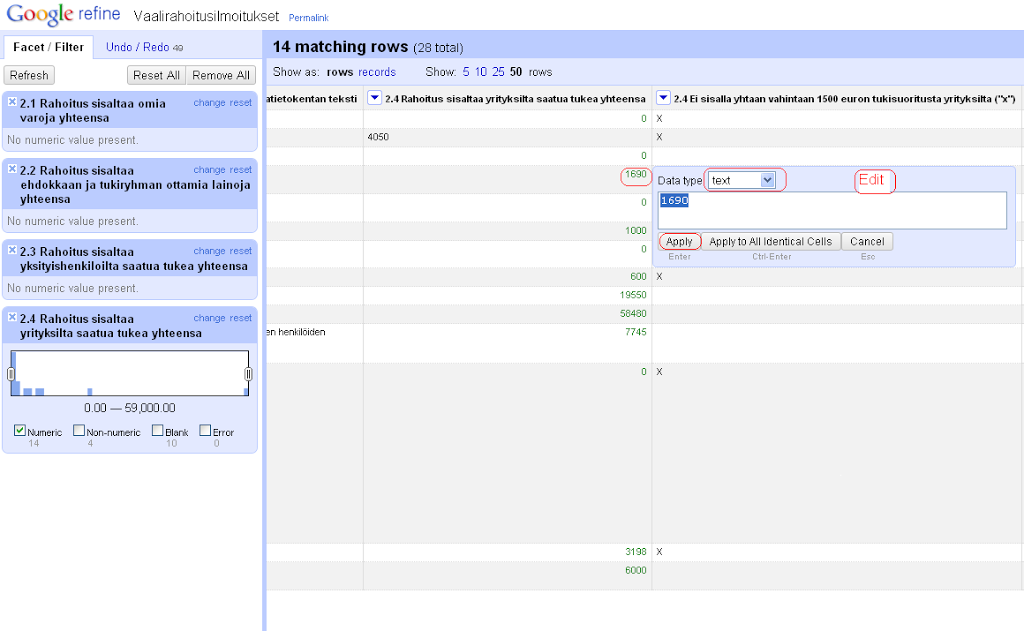
Rahasummia tullaan laskeskelemaan ja vertailemaan. Niiden on siis syytä olla tietotyypiltään samanlaisia. Annoin Refinen lukufasetin (numeric facet) käydä läpi kaikki ne Puoluerahoitusvalvonnan taulukon sarakkeet, joissa oli rahasummia. Suurin osa oli tekstityyppiä, mutta joukossa oli myös numeerista dataa.
Valtavirrasta poikkeavat taulukon solut editoidaan. Kaikille tekstityypi, klik, done. Tällainen “masterdatan” muokkaaminen ei tietysti ole riskitöntä.
Taulukkolaskentaohjelmistot tarjoavat monenlaista vipstaakia datan sisäänlukuvaiheessa. Kokeilin, miten vahingossa mukaan livahtaneet hipsut ja ylimääräiset tyhjät merkit pystyy poistamaan. Pystyy, helposti.
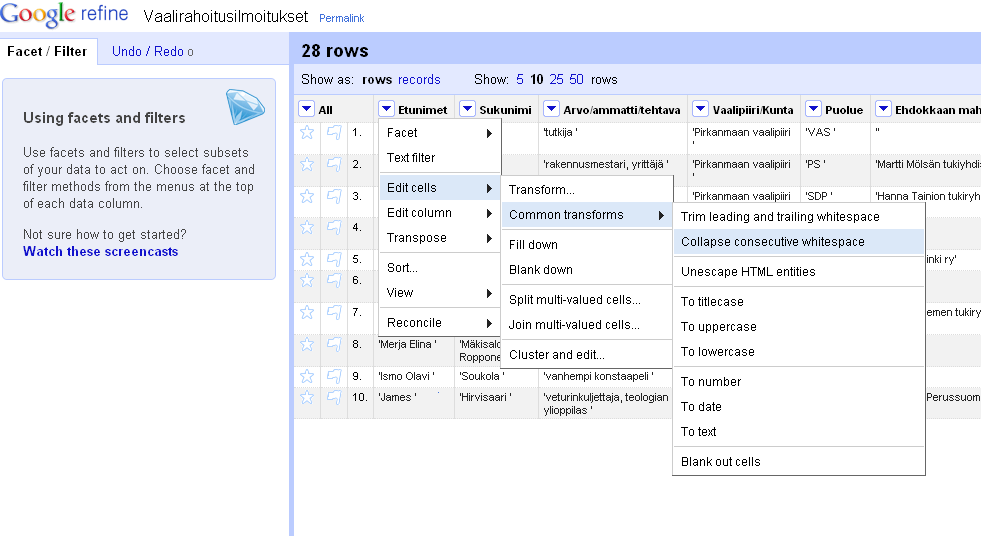
Google Refine Expression Language (GREL) ymmärtää säännöllsiä lausekkeita. Alla poistetaan Etunimet-sarakkeen soluista lopun tyhjät merkit ja sulkeva hipsu.
Google Fusion Tables
Pinserissä oli muutama viikko sitten mainio salapoliisitarina iPhone-paikkadatasta. Siitä luin ensimmäistä kertaa näistä fuusiotauluista. Kätevä apu datan kääntelyyn ja katseluun eri kanteilta. Ja jos mukana on paikkatietoa – kuten Pinserin tapauksessa – ne esitetään automaattisesti karttanäkymässä. Taulukkoon voi tallentaa näkymiä, ja näkymiin edelleen suodatuksen ja ryhmityksiä.
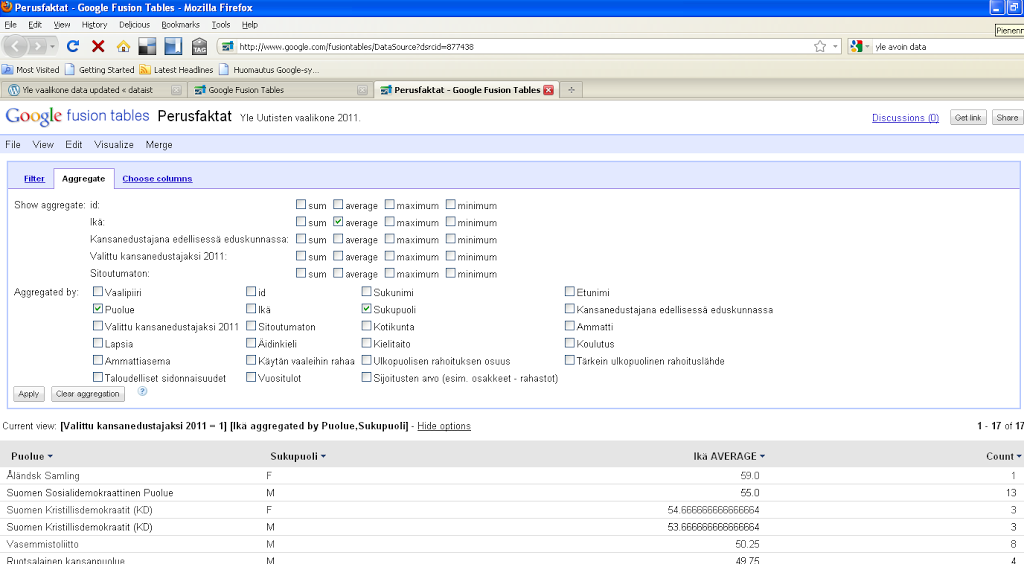
Tein YLE:n vaalikonedatalle näkymän, jossa ovat ehdokkaista vain perustiedot kuten nimi, ikä, sukupuoli, puolue jne. Suodatin jäljelle vain ne rivit, jotka liittyvät valittuihin ehdokkaisiin. Ryhmitys keskimääräisen iän ja puolueen mukaan.
Erilaisten näkymien ja ryhmittelyjen määrittely data-aineistolle lähestyy pivot-taulujen filosofiaa. Excel ja OpenOffice Calc ovat tunteneet ne jo pitkään, ja aivan hiljattain niille tuli aito tuki myös Google Docsiin. Olen yksi heistä, joille pivotointi on vielä varsin vierasta. Tony Hirstin maanläheinen blogaus on auttaa alkuun.
Paikkatiedosta puheenollen, leikittelin jonkin aikaa ajatuksella, että saisin ennen HS Openia käsiini jonkin eduskuntavaaliehdokkaan, jolla olisi ollut iPhone mukana vaalityössä. Grand Plan: oletetaan, että hän olisi halukas antamaan Tieteen käyttöön viimeisen vaalityöviikkonsa paikkadatan. Oletetaan edelleen, että hän olisi liikkunut nimenomaan omassa vaalipiirissään iPhonensa kanssa. Miltä näyttäisi visualisointi, jossa olisivat mukana hänen liikkeensä ja hänen kyseisessä vaalipiirissä saamansa äänet? Voisiko tästä vetää minkäänsortin johtopäätöksiä vaalityön vaikutuksista äänestyskäyttäytymiseen? No, vastaus on tietysti että ei voi 🙂 mutta sormiharjoitteluna se olisi ollut mukava. Terveiset ja kiitokst Jyrki Kasville, joka tuli ensimmäisenä mieleen, kun mietin keneen ottaa yhteyttä. Hän oli tehnyt vaalityötä Eduskunnan Nokia E90:n kanssa, koska siinä oli työpaikan kalenteri. Muita en tähän hätään ehtinyt saada kiinni.
Google Docs
Suurin osa tästä aurinkoisesta viikonlopusta meni Google Docsin kanssa mähkiessä. Kuvittelin näet voivani rakentaa sen avulla puuttuvan lenkin rahoitusdatan ja YLE:n vaalikonedatan välillä.
Olin muodostanut Google Refine’n transform-vivulla molempiin taulukoihin ylimääräisen apusarakkeen HloID, ehdokkaan sukunimi ja ensimmäinen etunimi. Tavoite: kopioida sen avulla YLE-taulun ID myös toiseen tauluun. Silloin minulla olisi kunnon avain.
Lopulta onnistui, edes osittain (mutta ei oikealla aineistolla, josta kohta lisää), kiitos ahkeran googlaamisen ja ystävällisten Google Docs -foorumin vakioauttajien.
=QUERY('Sheet2'!A:C,"SELECT C WHERE A CONTAINS """&A361&""" ")
Tässä ollaan työkirjan lakanalla Sheet1, B-sarakkeen (tuleva ID) solussa B361. Samalla rivillä, A-sarakkeessa, on HloID. Saman työkirjan lakanasta Sheet2, sarakkeesta A, etsitään vastaavaa merkkijonoa. Jos löytyy, saman rivin sarakkeesta C haetaan arvo soluun B361.
QUERY-lauseke on tallennettu ensimmäiselle datariville. Solun oikeasta alanurkasta kiinni, ja lausekkeen kopiointi taulukon kaikille riveille. Suhteellinen viittaus A-sarakkeen soluun kasvaa samalla automaagisesti.
So far so good. Mutta. Varsinainen taulukko on niin iso, että Google Docs ei suostukaan lukemaan sitä samaan työkirjaan. No, tämän ei pitäisi olla ongelma, sillä myös kokonaan toisesta työkirjasta voi hakea, ainakin teoriassa.
=QUERY(IMPORTRANGE("0AvfW9KgU1XzhdHJSRFFwSGR3YWR6MVl3X0ZVWkhibUE","Sheet1!A:C"),"SELECT C WHERE A CONTAINS """&A361&""" ")
Pitkä älämölö on työkirjan yksilöivä avain. Sen näkee URL:sta.
Ei onnistunut. Google Docs oli joko sitä mieltä, että C-saraketta ei ole tai että hittiä ei löydy. Joissakin ohjeissa lakana ympäröitiin yksinkertaisilla hipsuilla, toisissa ei. Joissakin käytettiin puolipistettä välimerkkinä, toisissa pilkkua.
Nyt te varmaan sanotte, että “miksi ihmeessä mokoma vaiva, tauluthan voi yhdistää simppelisti tällä tavalla…” ja näytätte. Jään odottamaan.
EDIT 23.5: Järjestäjät olivat tehneet paljon duunia datan eteen. Aineisto oli siististi kantatauluissa, kanta LAMP-palvelimella ja palvelin Amazonilla. Kiitos tämän, päivän annista tuli hyvä. Porukassa oli osaajia monelta alalta, ja nopea protoilu sujui. Lahjakasta väkeä!