The other day I requested my data from Instagram where I have had a public account since late 2012. Within one hour the data was ready for download. In my case, it was roughly 500 MB worth of JPG photos, MP4 videos, and metadata as JSON files.
What was perhaps a small surprise was that the likes data was not reciprocal. I have now detailed information about whose photos I have liked and when but who has liked mine? No record. The little I have looked at the Instagram API, you cannot fetch this information via it either.
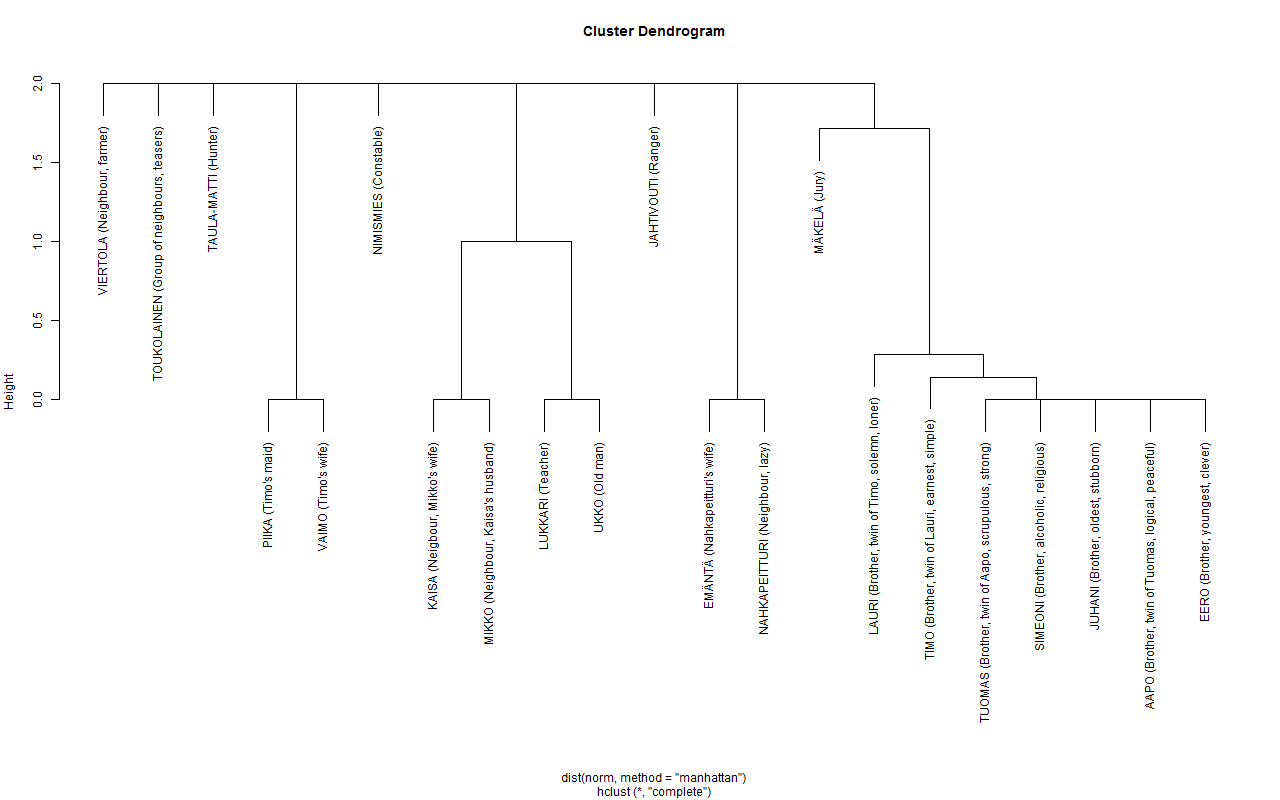
Below, as two separate images, is my liking behaviour over the years rendered as a calendar heatmap. The R code is on Github. Just about the only bigger thing I needed to do to the Instagram data was to fiddle with the data types so that I could input dates to the calendar function by Paul Bleicher.
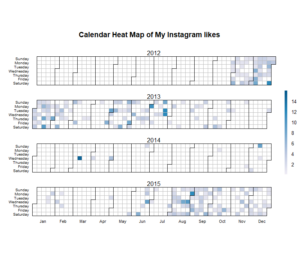

What about my own postings?
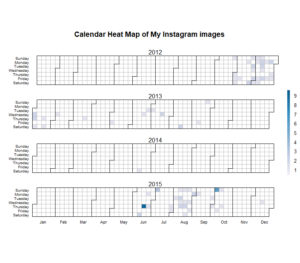

My first Instagram years I spent mostly watching, then gradually liking a bit more. It took some time before I started to contribute myself but after that, it’s been a rather steady stream of photos at a rate of 2 per day in average. Actually, somewhat under 2 because the original data doesn’t include zero-image dates.
Anyway, what are the photos about? Time to some elementary ML.
Something I was not aware of is that, following the concept of transfer learning, you can directly use pre-trained models to classify images. The most popular models are available via the Keras Applications API.
I found Transfer Learning in Keras with Computer Vision Models by Jason Brownlee to be a good hands-on introduction to the topic. The model used here for classification, VGG16, is popular for learning purposes I’m told. I also learned that VGG16 isn’t state-of-the-art any longer so I shouldn’t expect it to give anywhere near accurate results except perhaps in some limited classes. However, as it turned out, using the model against my images was an eye-opener, and a funny one at that!
I have a Windows machine and have been using Anaconda a little already so to get all that was still missing from the setup, Installing a Python Based Machine Learning Environment in Windows 10 by Frank Ceballos worked very well. Unlike Frank I prefer Jupyter Notebooks over the Spyder IDE but following his advice I first checked in its console that all packages were installed correctly. However, for coding I open Anaconda Navigator, select the PythonCPU environment I made, and launch Notebook.
In this ~13 MB Notebook I first print out a manually curated selection of some 90 images, their most likely class label according to the model, and its probability. Then, for the sake of statistics I gather all labels, and count the most frequent ones. I didn’t clock but the latter one took at least what felt like half an hour on my Lenovo ThinkPad X1 Carbon (Intel Core i7 CPU 18GB RAM)
As you can see from the individual images, if the photo features an animal and not much else, the model performs surprisingly well. Especially dogs seem to be well-trained (pun not intended) but other common mammals are not far behind. Other canines pose a challenge, see e.g. hare (37.17%) which is a jackal.
Among dog breeds, dalmatians are obviously easy, ditto chows. However, if the whole body is not visible, things get trickier. One notable exception in this respect is the pointer; almost exactly the right breed although you only see the head. At times, the dog hammer makes everything look like a nail, see wire-haired_fox_terrier (26.29%) !
From other animals, some species are universally easy. Chameleons, snails, lions, ibexes, bears, zebras… no other fauna quite resembles them – unless it’s a dog in a zebra suit! The weevil was almost too perfect for this exercise thanks to the solid white background.
Given the accuracy of labeling dogs, it baffled me why the model did not give notice at all to the gray poodle. Why instead an ashcan with 30% probability? Well, there is an ashcan in the lower left corner. A similar case is the moving_van (27.47%) where the by far most prominent object is a big mural of a bear. But, there is a van. What’s happening here? Is the lower left corner a hot spot of some kind?
In the code, by image, I retrieve the highest probability class with
label = label[0][0]
In these two photos, ashcan and van simply get a higher score than the other objects in the image. When I define
label = label[0][1]
the labels are returned as soft-coated_wheaten_terrier (28.72%) and bison (12.02%), respectively. Next highest probabilities that is, and now also with a dog breed. To continue, with
label = label[0][2]
the result is streetcar (7.90%) and Newfoundland (8.34%). In other words, we are not just ascending the probability tree but also moving towards slightly more abstract, or at least not so obvious, classes. Derived, if you wish.
The model cannot be fooled that easily. Parachute (69.60%) shows a piece of textile with two tropical birds, artistically drawn but still with distinct features of real-life bird species. No matter how much you lower the probability of the class, the model is adamant that the image is about texture, not animals: sleeping_bag (11.72%), pillow (8.84%), quilt (4.95%), shower_curtain (0.63%)
It is interesting how VGG16 reveals bits and pieces about its training set.
First of all, avian fauna is mostly American. The bird pic I lol’d the most at was boldly labelled bald_eagle (14.20%) The image shows a European starling up on a pine tree. Goldcrest is taken either a jacamar or hummingbird, depending on the angle, although with a lowish probability in both cases. Likewise, architectural classes tell about a society where the state-of-the-art construction for people to live in is a house, as it is in the US. This explains why local blocks of flats are grimly classed as prisons! What was also intriguing to notice was that images on commercial activities like various merchandise must have been well represented in training data. Otherwise I cannot understand why shoe_shop (84.31%) and butcher_shop (78.01%) were so spot on.
At first sight, on the level of all my 2000+ photographs, the VCC16 model does not seem to perform that good, which was expected. There are only so many clear images of animals. Yes, it is true that water is a frequent element in my shots, but lakeside and breakwater could have been elaborated on a bit more maybe, park_bench and stone_wall too. Yet, at the end of the day, I think that these top four labels do are quite accurate classes (although it’s mostly seaside rather than lakeside). And the rest? Some of them sound a bit odd.
Lines of text in the image is a hard nut to crack. Is it a book, book_jacket, menu, doormat, envelope, packet, or a web page? In my case it’s oftentimes a screenshot from a web page I guess. Besides, how would you classify an abstract and artsy image without any discernible shapes? There is no “right” class for them. That’s why the class can be anything really; maze, window_shade, fountain etc.
Let’s face it, I like to take (and post) obscure pictures. Especially if there is a shortage of dogs, benches, walls and water.
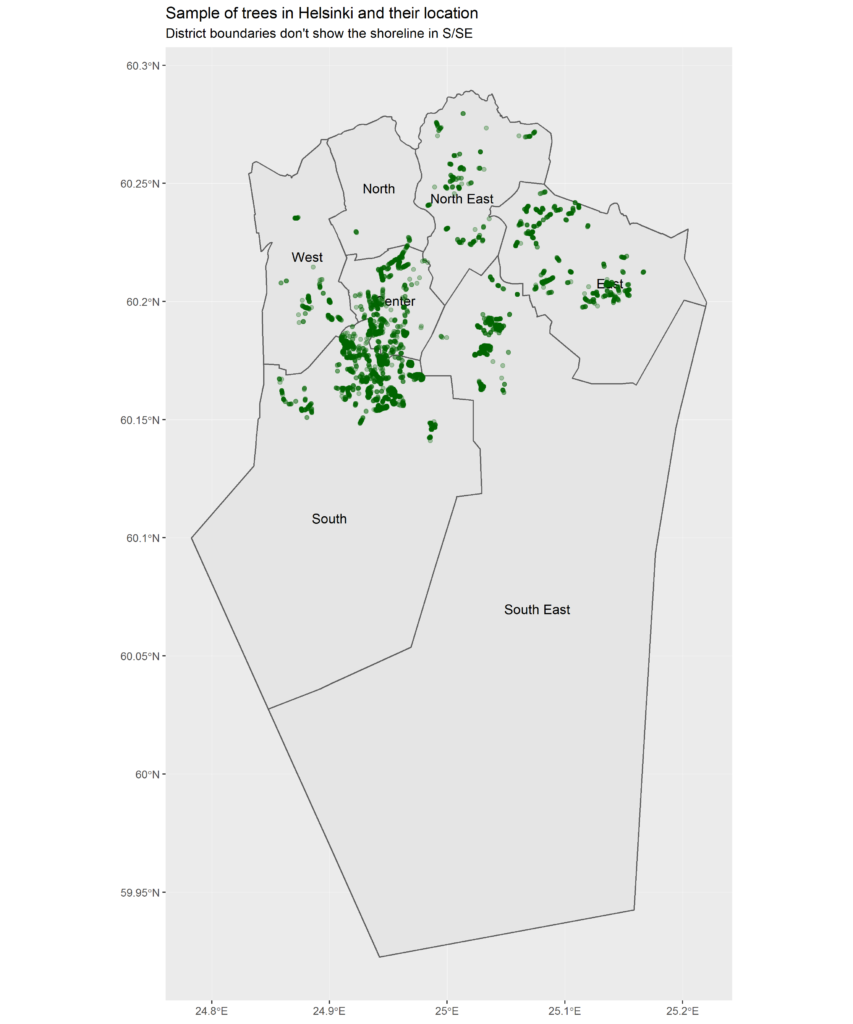

 More exactly, a
More exactly, a